ANATOMI, LOGIKK OG PEDAGOGIKK
- alfabetdannelse i Tolkien's Midgard
Av Anne Kari Sorknes
![]()
|
I denne artikkelen skal vi først se på en del
fonetikk og få den illustrert anatomisk. Deretter skal
vi se hvordan fonetikken og anatomien har dannet bakgrunnen
for utformingen av alfabeter i Tolkien's Midgard, og til slutt skal vi
se litt på hva dette kan ha å si for
leseopplæring. Som kilde har jeg brukt Tillegg E i Tolkien's "Ringenes Herre". |
|
Fonetikk Læren om lyder i sin alminnelighet kalles fonetikk. Læren om hvordan en setter opp lydsystemer for et gitt språk, kalles fonemikk - og slike lydsystemer er et nødvendig mellomstadium før det kan utarbeides et endelig alfabet for et språk. Vi skal begynne med fonetikken, for det er fonetikk vi snakker når vi beskriver lyder anatomisk. Men vi skal også se på lydsystemer og tenke litt fonemikk. |
|
Lyder og anatomi En lyd kan beskrives entydig anatomisk ved hjelp av 4 opplysninger:
|
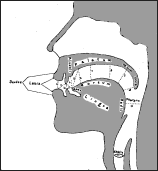 Fig. 1 (større utgave) |
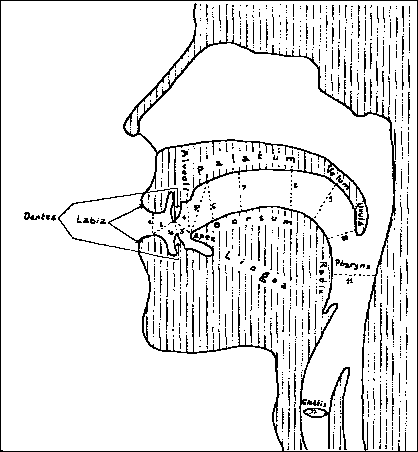
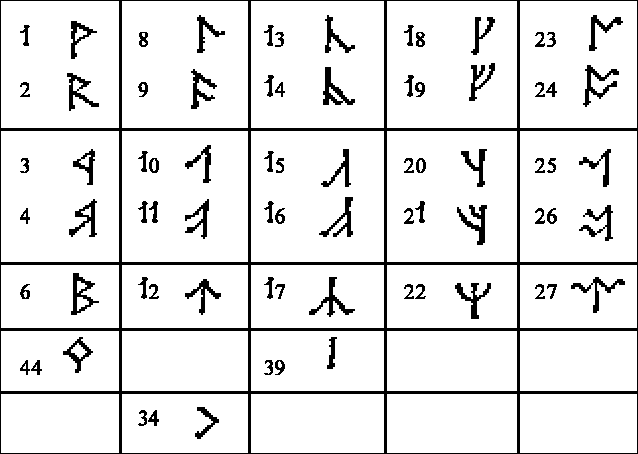
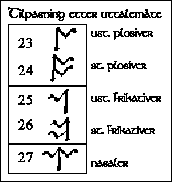
Konsonanter i ansiktsdiagrammer Jeg har valgt å bare behandle konsonanter, da jeg fant lite av vokalsystemer i alfabetene. Jeg konsentrerer meg om de konsonantene som best illustrerer grunnsystemet for lydene. Stedet en konsonant dannes på, kan vises ved en snitt-tegning av munnhulen, et ansiktsdiagram (se fig.1). Et skjema over alle konsonantene blir ordnet i samme retning som ansiktsdiagrammet, med de lydene som dannes med leppene, lengst til venstre, og de lydene som dannes nede i halsen, lengst til høyre. Nedover i dette skjemaet plasseres så de forskjellige måtene konsonantene dannes på. Jeg har plukket fra hverandre runene i Daerons angerthas og satt en del av dem inn i et slikt skjema (se fig.2), og kommer til å henvise til dem med runenummer. Dette skjemaet er satt opp fonemisk etter lydsystemene slik jeg finner dem hos Tolkien, ikke strengt fonetisk. |
{kind=link}
 Fig. 2 (full størrelse) |
Egner seg til praktiske øvelser! For dem som allerede har studert fonetikk, vil dette være kjent stoff. For andre vil det til nå kanskje ha virket litt teoretisk. Men prøv å ta det som en praktisk bevisstgjøring på hvordan vi egentlig bruker de ulike delene av munnen når vi snakker, på hva som er viktig når vi skal "ar-ti-ku-le-re ty-de-lig". Og prøv dere fram på de lydene som dere ser det er plass til (og kanskje runer for) i skjemaet, men som det ikke blir sagt så mye om. Kanskje er noen av dem gamle kjente. |
{kind=link}
 Fig. 3 |
Ulike måter å danne leppelyder på Vi begynner ytterst, med de lydene som dannes med begge leppene lukket fast eller løst sammen. Fordi de dannes med to lepper (labia), kalles de bilabiale. Dette betegner stedet hvor de dannes. Måten de dannes på, utgjøres av måten leppene brukes på. |
 |
Plosiver Den første måten vi skal se på, har tre atskilte faser. Først lukkes leppene fast sammen, deretter bygges det opp trykk inne i munnen bak leppene, og til slutt slippes trykket raskt ut som en eksplosjon. Derfor kalles lyden en plosiv. Et annet navn på den er støt. Den kan være ustemt eller stemt, dvs. med åpen stemmespalte eller med stemmebåndene vibrerende. Den ustemte lyden kjenner vi igjen som en p (rune nr.1), som altså er en ustemt bilabial plosiv. Vi bruker den på norsk i ordet "pappa". Den stemte lyden vil være en b (rune nr.2), som i ordet "bade". Lukkefasen er gjengitt på ansiktsdiagrammet for p (se fig.3). Vi ser der at åpningen opp til nesehulen er stengt. |
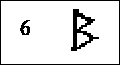 |
Nasaler Hvis vi lukker leppene fast sammen som til en bilabial plosiv, men åpner opp til nesehulen og lar lufta gli ut gjennom nesa, får vi en lyd som kalles en nasal. Det er mest vanlig med stemte nasaler, og en stemt bilabial nasal vil vi kjenne igjen som en m (rune nr.6), som i "mamma". |
|
Frikativer En tredje måte å danne bilabiale lyder på, er å lukke leppene ganske løst sammen, slik at lufta glir ut mellom dem og skaper friksjon. Særlig ved stemte lyder kan denne friksjonen kjennes tydelig. Disse lydene kalles frikativer. Et annet navn på dem er spiranter. Bilabiale frikativer finnes blant annet i spansk (og skrives da gjerne med b som i "Marbella"), men ikke på norsk. |
 Fig. 4 |
Når tenner møter lepper En frikativ som vi kjenner bedre fra norsk og engelsk, dannes på et litt annet sted enn bilabialene. Hvis vi ikke lar leppene møtes, men lar tennene i overmunnen berøre underleppa, og så lager lyd med friksjon, får vi henholdsvis f (rune nr.3) som i "far" og v (rune nr.4) som i "vår" som ustemt og stemt lyd. Her er det bare én fase, som vises i ansiktsdiagrammet for f (se fig.4). Disse lydene, som dannes med lepper og tenner, kalles labio-dentale. Det går an å danne labio-dentale nasaler og plosiver også, men disse er sjeldne. |

|
Litt fonemikk Når vi snakker fonetikk, må vi være nøyaktige og angi alle de små forskjellene. Når vi derimot snakker fonemikk, er poenget å gruppere sammen lyder som ligger nær hverandre, og overse forskjeller når dette ikke fører til forvekslinger. I et språk som bruker både bilabiale og labio-dentale varianter av samme lyddanningsmåte, er stedsforskjellen viktig også fonemisk sett. Men i språk hvor forskjellige måter plasseres på hver sine nabosteder, kan disse stedene gjerne slås sammen til ett område. På norsk og engelsk (og så langt jeg kan se, på de eldarinske språkene og på vestrønt) er nasalen og plosivene bilabiale, mens frikativene er labio-dentale. Fonemisk sett er det da mest systematisk å slå disse sammen til ett område, labialer. Vi vet i dette tilfellet at det er små detaljforskjeller i nøyaktig sted for labialene etter som om de er nasaler, plosiver eller frikativer. |
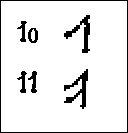 |
Flere frikativer Vi skal se på enda flere steder der det går an å danne frikativer, og flytter oss lenger inn i munnen. Med å sette tungespissen ut mellom tennene og lage friksjonen der, får vi en inter-dental frikativ. Denne kjenner vi som den engelske th-lyden. (Rune nr.10 er den ustemte lyden, som i engelsk "think", og rune nr.11 er den stemte, som i "this".) I likhet med de frikativene vi alt har sett på, dannes denne med tunga helt flat. |
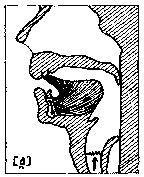 Fig. 5 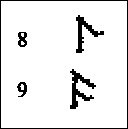 |
Hule frikativer Hvis vi runder tungespissen så den får et lite hulrom midt på, får vi en slags lespelyd. En slik hul frikativ er vanligere å danne med tungespissen mot fortennene, en dental lyd. Denne kjenner vi som s, som i navnet "Sissel". (Rune nr.34 er en av runene som brukes for den ustemte lyden.) 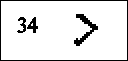 Her er det igjen en systematisk fordeling av stedsplasseringen av lyddanningsmåtene. De flate frikativene er inter-dentale, mens de hule frikativene, plosivene og de andre lydene er dentale. Her er det også nyttig fonemisk sett å snakke om et dentalt område og kalle alle disse lydene dentale. På norsk har vi både ustemt dental plosiv (rune nr.8), t som i "tørr", og stemt dental plosiv (rune nr.9), d som i "dør". Den stemte er avbildet i ansiktsdiagrammet for d (fig.5). |
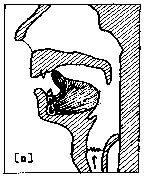 Fig. 6 |
Den harde gane Den tilsvarende nasalen er n (rune nr.12), som i ordet "norsk". Ansiktsdiagrammet (fig.6) viser en lyd som er mer alveolar (dannet mot den harde gane) enn dental, men vi tar også denne med i det dentale området. 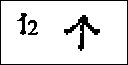
|
 Fig. 7 Fig. 7 Fig. 8 Fig. 8 |
Den bløte gane Nå kommer vi så langt inn i munnen at det ikke er snakk om plassering av tungespissen, men av tungeryggen. Avhengig av hvor langt inne på den bløte gane tungeryggen har kontakt, kalles lyden palatal eller velar. På begge disse stedene kan det dannes plosiver, nasaler og frikativer. Som ustemt palatal frikativ kjenner vi den norske kj-lyden som brukes i ordet "kjøtt". En stemt variant av denne kan ligne på en j (nesten som i "jul"), men med kraftig friksjon. Plasseringen vises i ansiktsdiagrammene (se fig.7 - kj - og 8 - j). Palatale nasaler ("nj-lyd", som i "hainnhoinn i bainn") og palatale plosiver (jfr. en uttale av ordet "ikkje" eller kanskje "itj") forekommer i norske dialekter. |
 Fig. 9  |
Palatale varianter Det finnes også en litt annen utgave av palatale lyder. Fonetisk sett er disse ikke rent palatale, men palato-alveolare, altså dannet mellom den harde og den bløte gane. Fonemisk kan de slås sammen med de andre til ett palatalt område - som sagt forutsatt at det ikke fører til forvekslinger. Slik jeg forstår Tolkien, hadde forskjellige språk hver sin utgave. Da kan språket avgjøre den nøyaktige uttalen av en "palatal rune", og det trengs bare ett sett med tegn. Som ustemt hul palato-alveolar frikativ kjenner vi den norske sj-lyden, som i "sjokolade" (både denne og kj-lyden dekkes av rune nr.15). Ansiktsdiagrammet (se fig.9) viser her hvordan sidene på tunga har kontakt med ganen, mens midten av tunga danner et hulrom. Den stemte lyden finnes blant annet på fransk, som i navnet "Jeanne d'Arc", men ikke på norsk. (Både denne og flat palatal frikativ dekkes av rune nr.16.) |
 |
Affrikater I stedet for en ren plosiv tar vi her med en mellomting mellom (eller en kombinasjon av) plosiv og frikativ, en affrikat. Ustemt palato-alveolar affrikat er den lyden vi har på norsk i ordet "tsjekkisk". Den er mer vanlig på engelsk, og finnes der også i stemt utgave, som i navnet "John". (Både affrikatene og plosivene dekkes altså her av runene 13 og 14, ustemt og stemt.) |
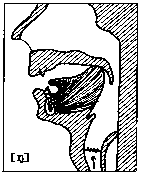 Fig. 10 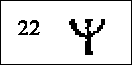 |
Velare lyder Velare plosiver er vi vant med fra standard norsk, da dette er vanlig k som i "katt" (rune nr.18) og g som i "gris" (rune nr.19). Stemt velar nasal kjenner vi som ng-lyden (rune nr.22), som i "synge". Ansiktsdiagrammet for denne viser velar plassering (se fig.10). På norsk er vi ikke vant med å ha denne lyden først i ord, bare midt i eller til slutt, som i "sang". Men det finnes andre språk hvor ord kan begynne med "ng". 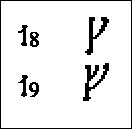
|
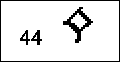 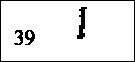 |
Labialiserte velarer: Halv-vokaler De velare lydene kan også uttales med rundede lepper, og kalles da labialiserte. Det er dette som er det spesielle ved runeserien 23-27 (se skjemaet fig. 2). Det er vanlig å skrive det med en w sammen med den labialiserte lyden. Dette tegnet har vi fra den engelske w-lyden, som er en mellomting mellom en konsonant og en vokal, og kalles en halv-vokal. Engelsk w som i ordet "we" er en stemt labial halv-vokal (rune nr.44). Vår egentlige norske j, som i "jul", er en stemt palatal halv-vokal (rune nr.39). |
|
Logisk skjemainndeling Vi ser av dette at rubrikkene i skjemaet over stedene hvor lydene dannes, er logisk ordnet i kolonner fra venstre mot høyre etter anatomien i munnen. Noen slik logisk rekkefølge for måtene lydene dannes på, gir seg ikke anatomisk, men hvis en har bestemt seg for en rekkefølge, kan alle konsonanter plasseres i rader i skjemaet i henhold til denne. Vi har hoppet over flere måter og mange steder som lyder kan dannes på, og vi har dessuten forenklet skjemaet fonemisk. En hvilken som helst konsonant vil ha sin faste plass i et fullstendig, fonetisk oppsatt skjema. |
|
Fig. 2 (full størrelse) |
Logisk utforming av alfabeter Den anatomiske logikken blir utnyttet, først av tengwar, og senere også av Daerons angerthas. Vi ser på fig.2 igjen, hvor rekkefølgen i runerekka er brutt opp for å passe inn i skjemaet, fordi det da er lettere å se hvordan alfabetet utnytter logikken. |
|
"Lik lyd - lik form"-prinsippet Hver av de loddrette kolonnene, som inneholder lyder som dannes på samme sted, har tegn med samme grunnform. Hver av de vannrette radene, som inneholder lyder som dannes på samme måte, endrer grunnformen på samme måte. Lyder som ligner hverandre på samme måte i uttale, har også tegn som ligner hverandre på samme måte i utseende. |

|
De forskjellige grunnformene etter uttalested Grunnformen er den ustemte plosiven. Alle runene har en rett stamme med en eller flere grener på skrå ut fra stammen. På ustemte plosiver er det én gren som sitter til høyre for stammen. På den labiale er grenen en lukket trekant (rune nr.1). På den dentale går grenen nedover fra toppen til midten av stammen (rune nr.8), på den palatale nedover fra midten til bunnen av stammen (rune nr.13), og på den velare oppover fra midten til toppen av stammen (rune nr.18). På den labialiserte velare går så grenen litt nedover fra toppen og deretter utover opp til toppen igjen (rune nr.23). |
 |
Tilpasning av grunnformene etter uttalemåte For å gjøre plosiver om til frikativer, flyttes grenen over fra høyre til venstre. For å gjøre ustemte lyder om til stemte, føyes det på en ekstra gren på samme side. For å gjøre plosiver om til nasaler, settes grenen på begge sider av stammen. Her er det kanskje litt manglende konsekvens med hensyn til stemte og ustemte nasaler, men dette kommer av at ustemte nasaler ikke fantes i disse språkene, og derfor ikke trengte egne tegn. Det var også spesielle forhold som gjorde at rune 6 måtte ta plassen til rune 5. |
|
Regne ut angerthas-tegnene logisk For å lære seg hovedtegnene i angerthas, er det derfor nok å lære rune nr.1, nr.8, nr.13, nr.18 og nr.23. Kan du disse, og vet hvordan du gjør om en lydgruppe til en annen, kan du regne deg til hvordan rune nr.2-4, 9-12, 14-17, 19-22 og 24-27 skal være. Fordi dette alfabetet bruker "lik lyd - lik form"-prinsippet, kan du langt på vei resonnere deg fram logisk både til hvordan et tegn skal leses og til hvordan en lyd skal skrives. |
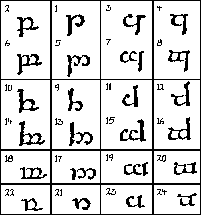 Fig. 11 (full størrelse) |
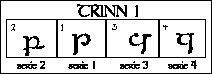
Mer fleksibel utnyttelse av systemet i tengwar Tengwar var først ute med å utnytte "lik lyd - lik form"-prinsippet, og angerthas ble påvirket av dette. Men tengwar brukte det på en enda mer fleksibel måte. Angerthas hadde en fast rekkefølge på alfabetet, og ramset det opp slik vi er vant med. Tengwar hadde ikke noen slik ramse, men et bokstavsett som var stilt opp i et skjema omtrent som det fonemikkskjemaet vi satte lydene inn i (og vi bytter her plass på kolonnene så det samsvarer enda mer med fonemikkskjemaet, se fig. 11). Mens angerthas hadde faste lydverdier for hver rune, var bokstavene i tengwar fleksible så fonemikerne kunne ta dem i bruk etter hvert enkelt språks behov. Samme bokstavsett ville kunne tas i bruk av språk som hadde svært forskjellig lydsett. Det er tydelig at settet er satt opp etter samme prinsipper som lingvistene bruker den dag i dag. |
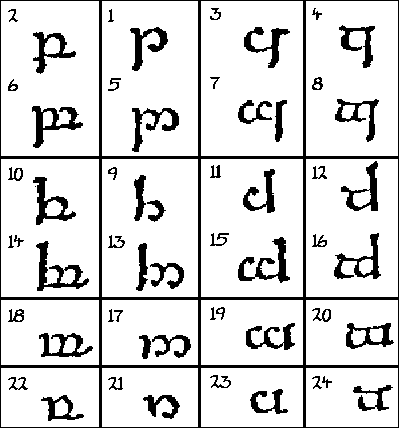{kind=link}
 (full størrelse) |
"Lik lyd - lik form" igjen Det samme gjelder her som for angerthas: Lyder som ligner hverandre på samme måte i uttale, har også tegn som ligner hverandre på samme måte i utseende. De loddrette kolonnene kalles serier (témar), og de vannrette radene kalles trinn (tyeller, eng.: grades). Hver serie inneholder lyder som dannes på samme sted, og de har tegn med samme grunnform. Hvert trinn inneholder lyder som dannes på samme måte, og de endrer grunnformen på samme måte. |
{kind=link}
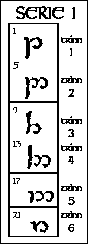 (full størrelse) |
Tilpasning av de forskjellige grunnformene De 24 grunnbokstavene i tengwar (se fig. 11) er ordnet i 4 serier med 6 trinn i hver. (Utenom disse er det en del tilleggsbokstaver, som vi ikke ser på her.) Alle grunnbokstavene består av en stamme (telco) og en bue (lúva). Trinn 1 ble regnet som grunnformen. Her starter stammen i høyde med buen og fortsetter ned under linjen som bokstaven står på. I serie I er buen åpen og plassert på høyre side av stammen, i serie II er den lukket, og fortsatt på høyre side. I serie III er buen åpen og plassert på venstre side, og i serie IV er den lukket, og fortsatt på venstre side. Trinn 2 har ingen forandring av stammen, men buen er fordoblet. Trinn 3 og 4 har stammen hevet, og trinn 5 og 6 har den forkortet. Dessuten har også trinn 4 og 5 buen fordoblet. |
{kind=link}
|
Valgfri modus etter språkets behov Uttalestedet for hver serie, og lyddanningsmåten for hvert trinn, vil variere fra språk til språk. Hvert språk velger de stedene og de måtene som faktisk brukes i språket. Trinnene kan betegne en lang rekke forskjellige måter å danne lyder på. Settet kan forskyves så seriene plasseres på forskjellige steder. Hvis det blir for få serier, kan en bruke en av seriene om igjen med f.eks. ekstra prikker under bokstavene (dette gjøres i quenya). Dette er svært nyttig, fordi det kan være store variasjoner språk imellom. Hvert språk får sin modus som angir hvordan dette språket bruker bokstavene. |
|
Modus for noen midgardske språk I tredje tidsalder hadde det nedfelt seg en praksis med at serie I ble brukt for dental-lydene (tincotéma), mens serie II ble brukt for labial-lydene (parmatéma). For serie III og IV var det større variasjoner. |
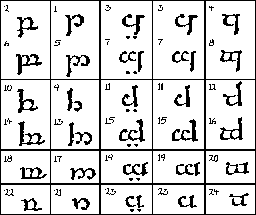 Fig. 12 (full størrelse) |
Quenya Quenya hadde både palatale lyder (tyelpetéma, som var flate frikativer og plosiver), velare lyder og labialiserte velare lyder (quessetéma). Serie IV ble her brukt for de labialiserte velarene. Velar-lydene ble gjengitt med serie III, og den samme serien med to prikker under bokstavene ble også brukt til palatal-lydene. (Se fig.12.) |
{kind=link}
|
Fig. 11 (full størrelse) |
Vestrønt Vestrønt hadde som palatale lyder de hule frikativene og affrikatene, og brukte serie III for disse. Serie IV brukte de så for velar-lydene (calmatéma). (Se fig.11.) Trinnmodus i vestrønt Hva de ulike trinnene skulle betegne, hadde det også nedfelt seg en viss praksis for. Det følgende skulle kunne beskrive en modus for vestrønt. Quenya brukte trinnene litt annerledes (vi går ikke inn på det her) - språket hadde sine egne spesielle behov, og systemet skulle jo nettopp være fleksibelt. Trinn 1, grunnformene, ble gjerne brukt til de ustemte plosivene. Fordobling av buen gjorde en lyd stemt (trinn 2, 4 og 5). Å heve stammen, som i trinn 3 og 4, gjorde plosiven om til en frikativ, og å forkorte stammen, som i trinn 5 (og 6), gjorde plosiven om til en nasal. Etter denne logikken skulle trinn 6 være ustemte nasaler. Ettersom slike ikke fantes i disse språkene, kunne dette trinnet brukes til noe annet, og ble da gjerne brukt til stemte halv-vokaler. |
|
(full størrelse) |
Regne ut tengwar-tegnene logisk På samme måte som i angerthas trenger du ikke å pugge hele bokstavsettet. Du kan regne deg fram til bokstavene, fordi systemet er logisk ordnet etter fonemikken. (Ett sted bryter likevel logikken i bokstavbruken med logikken anatomisk sett: Serie I og II har byttet plass i skjemaet i forhold til plasseringen av lydene i munnen. Ellers ligner bokstavskjemaet på fonemikkskjemaet. Vi bruker fonemikkskjemaets oppsett her.) Det er nok å lære serie I (med alle variasjonene) og trinn 1 (i alle grunnformene) i riktig modus for det språket du vil bruke. Hvis du kan disse, vet du hvordan du gjør om en lydgruppe til en annen, og da kan du regne deg til hvordan resten av bokstavsettet skal være. Dette alfabetet bruker også "lik lyd - lik form"-prinsippet. Derfor kan du også her langt på vei resonnere deg fram logisk både til hvordan et tegn skal leses og til hvordan en lyd skal skrives. (full størrelse) |
|
Leseopplæring Dette høres jo genialt ut. Og det tiltaler min sans for systemer! Men så kommer pedagogen i meg og begynner å snakke om leseopplæring og leseteknikk, og minner meg om den tiden da jeg underviste norske førsteklassinger i lesekunsten. Ville et slikt system ha gjort det lettere for dem? Og var systemet i Midgard til hjelp eller til hinder for alvebarn og hobbitbarn som skulle lære å lese? |
|
Har vi nytte av logikken? Etter alt dette vi har sagt om den systematiske logikken alfabetet er oppbygd etter - så bruker du den ikke når du leser! Det kan være greit nok med logisk resonnement når du skal tyde en gravskrift eller innskriften over ei dør. Men det går altfor sakte når du skal lese Vestmarks røde bok! Så lenge vi staver oss gjennom et ord bokstav for bokstav, da kan vi ha nytte av å bruke logikken. Men all leseopplæring går ut på å føre oss forbi det stadiet der vi staver bokstav for bokstav, og over til et stadium der vi ser hele ord, til og med hele ordgrupper, som en enhet. (Noen leseopplæringsmetoder begynner faktisk i denne enden, med å lære eleven hele ordbilder, og etterpå trekke ut bokstavene fra ordene.) |
|
En modell for leseopplæring Det finnes mange teorier om hva det egentlig er å lære å lese. Jeg vil sette opp en modell for hvilke prosesser som kan være inne i bildet, og vurdere i hvilken grad det logiske systemet kan være til nytte for disse. |
|
Bokstavinnlæring Barna - eller den voksne som skal lære seg et språk med et alfabet han ikke kjenner - må begynne med bokstavinnlæring. Det er her jeg tror logikken kan komme mest til nytte, særlig for den voksne. Barna vil kanskje ikke forstå systemet godt nok til å ha så mye nytte av det. Men den voksne kan få hjelp av systemet til å forstå hvorfor bokstaven ser ut akkurat slik som den gjør, og det vil gjøre førstegangsinnlæringen lettere. |
|
Fare for forveksling Ulempen er at når det er gått noen dager, vil det kanskje være vanskeligere å holde fra hverandre de nyinnlærte bokstavene når både lyder og former ligner så mye på hverandre. Bokstaver som er lette å forveksle lydmessig, vil også være lette å forveksle formmessig. Øret og øyet vil ikke få noen hjelp av hverandre, men ha de samme problemene. Dette kan bli et problem for barn som har tungt for å lære. Og det vil kanskje bli et enda større problem for barn som ikke har tungt for å lære, men som derimot lider av dysleksi (ordblindhet). |
|
Automatisering av bokstavtolkingen Etter bokstavinnlæringen kommer selve leseinnlæringen. I denne inngår først bokstavtolkingen. Det er det vi gjør når vi staver oss gjennom et ord bokstav for bokstav og "drar sammen lydene". Hvis vi da er usikker på en bokstav, kan systemet kanskje hjelpe oss med å lete oss fram til hvilken det er - men det tar tid, og vi mister flyten i ordet. Skal det bli flyt i lesingen, har vi ikke tid til stadig å arbeide oss gjennom et logisk resonnement. Bokstavtolkingen må automatiseres, den andre delen av leseinnlæringen. Og her er jeg redd for at når bokstavene ligner hverandre så systematisk, blir dette ekstra vanskelig. |
|
Stor forvekslingsrisiko vanskeliggjør
automatiseringen Prinsippet for logisk resonnement er likhet og sammenheng. Prinsippet for automatisering av bokstavtolking er det motsatte: Ulikhet og karakteristisk egenart! For å kunne automatisere lesingen må du huske hver enkelt bokstav og raskt se forskjell på den og alle de andre. Da er det en fordel at bokstavene er så ulike som mulig. "Lik lyd - lik form"-prinsippet er altså egentlig til hinder på dette stadiet. |
|
Lesevennlig skrift? Her uttaler også typografer seg, og snakker om lesevennlighet. De sier at ulike skrifttyper kan være med på å gjøre det lettere eller vanskeligere å lese raskt sammenhengende. De vil nok karakterisere tengwar som en svært lite lesevennlig skrift. (Derimot er den usedvanlig dekorativ!) I tillegg til de bokstavene som er lette å forveksle to og to, er alle bokstavene lette å forveksle med hverandre, fordi de alle har buen som det mest iøynefallende trekket. I angerthas er det flere trekk som skiller de ulike formene fra hverandre, så det vil nok være lettere å lære. |
|
Flyt i lesingen Automatisering av lesing kommer ved at en ser ordene igjen og igjen, helt til en ikke lenger tenker over hva hvert enkelt tegn i ordet er, men ser det som en enhet. Det kan sammenlignes litt med å slå opp i en tabell: Til å begynne med har en bare løse bokstaver i tabellen, men siden kommer det også hele ord der, som en kan slå opp på direkte. Å se en ordgruppe som en enhet betyr ikke å tolke hver enkelt bokstav i ekstra høy hastighet. Det betyr å tolke hele bildet av ordgruppen under ett, å slå det opp direkte i tabellen. Dette forutsetter at bokstavtolkingen er blitt helt automatisert. Først da har en nådd det siste stadiet i opplæringsmodellen: den egentlige lesingen. |
|
Strevsomt, men ikke umulig Problemene med at tengwar- og angerthas-tegnene er så lette å forveksle, fører ikke til at det er umulig å automatisere bokstavtolkingen i disse alfabetene. De fører bare til at en trenger å se ordet så mange flere ganger før det sitter, slik at automatiseringen tar lenger tid enn den ville gjort med et alfabet hvor det var lett å skille bokstavene fra hverandre. Dette vil særlig gi seg utslag for barn med slike problemer som vi nevnte tidligere. |
|
Ikke resonnement i automatisert lesing Når en har lært å lese, er en nådd til det stadiet der en ser ord og ordgrupper som en enhet. Dette forutsetter, som vi så, at bokstavtolkingen er blitt helt automatisert og ikke krever tankearbeid - og dermed er den logiske tenkningen, i det fine, logiske systemet, satt utenfor. Den har ikke noe i virkelig lesing å gjøre. |
|
Pedagogiske problemer i Midgard? Fører så det logiske systemet til pedagogiske problemer i Midgard, siden logikken ikke har noe i lesingen å gjøre, men fører til at automatiseringen av bokstavtolkingen tar lenger tid? I prinsippet ja - men jeg tror at forholdene i Midgard likevel gjør at problemene blir minimale. Kan det for eksempel tenkes alvebarn som har tungt for å lære? Jeg kan ikke engang forestille meg at det skulle finnes alvebarn som plages av dysleksi. Og tid skulle da alvene ha nok av til å kunne fordype seg i tekster både vel og lenge. |
|
Hobbiter med sin egen løsning? Blant hobbitbarna kan det nok derimot ha vært litt av hvert. Men jeg tror hobbitene hadde sin egen løsning på det. Jeg synes ikke det ville passe med deres mentalitet å presse lesesvake barn til å streve i timesvis med å komme seg gjennom pedagogiske øvingstekster. De lot nok disse barna få gjøre noe morsommere i stedet. Så overlot de lesingen til de barna som frydet seg over å oppdage lesekunsten og over å få mulighet til å lese slektsregistrene sine helt på egen hånd. |
|
|
Tillegg: Test deg selv!  Fig. 13 (full størrelse) - Finn løsningen i fasiten Prøv hva du selv gjør når du leser! Tengwar-teksten (fig.13) og angerthas-teksten (fig.14) er vanlig norsk nynorsk og bokmål. Jeg har prøvd å la skriftvalget passe til tekstinnholdet. Skriftvalg avgjøres også ofte av skriveredskap. Mitt skriveredskap er godt egnet for angerthas, men er nok litt for bastant til å yte tengwar full rettferdighet.  Fig. 14 (full størrelse) - Finn løsningen i fasiten Jeg har lagd en modus for norsk, og lar tekstene følge norsk ortografi (men med aa for å), ikke norsk uttale, så alle stumme konsonanter er med. Den bygger på vestrøn modus. Angerthas-teksten bruker Daerons runerekke, uten de endringene som senere utviklet seg i Moria, da disse beveger seg bort fra den fonemiske logikken. (De er derimot brukt i gravskriften på Balins grav, og Tolkien bruker dem i teksten på tittelbladet til Ringenes Herre.) |
{kind=link}
{kind=link}
|
Hvilken leseprosess bruker du? Test deg selv, særlig du som er vant med å lese tengwar og/eller angerthas - hvilken prosess bruker du? Resonnerer du deg fram til lydverdien av bokstaven, eller har du alt automatisert tolkingen? Og du som ikke er vant med det - synes du at du har nytte av å resonnere, eller slår du bare opp i bokas liste over tegnene? Se også etter om du synes den ene skriften er mer lesevennlig enn den andre. Mine observasjoner fra å ha testet dette i en gruppe, var at de fleste slo opp i lista (inklusive meg selv da jeg lagde oppgaven). Ingen brukte logisk resonnement ut fra det fine systemet - det tok nok for lang tid. Først offentliggjort i Angerthas, nyhetsbrevet til Arthedain - Norges Tolkienforening. Senere noe bearbeidet for nettbruk. |
Grafikken er levert av aks. og Mousepad

Anne K. Sorknes 
Til temamenyen 
Til forrige nivå:
Egne tekster
Bokstavtegn fra Tillegg 3 i "Ringenes Herre"
Ansiktsdiagrammer fra Summer Institute of Linguistics
Bakgrunn Copyright © Loraine Wauer Ferus